Further Insights
CLLR.pooled (Log Likelihood Ratio Cost): a numerical parameter summarizing the overall system quality, given by Eq. (1).
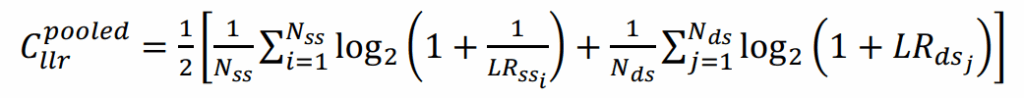
LR.ss are the likelihood ratio values for comparisons of the same speaker, while LR.ds are the likelihood ratio values for comparisons between different speakers. Since very high LR.ss values support the same-speaker hypothesis better, and very low LR.ds values support the different-speakers hypothesis better, smaller CLLR.pooled values indicate better performance. Conversely, a system that provides no useful information and always responds with a likelihood ratio of 1 will have a CLLR.pooled value equal to 1.
95% Credible Interval (CI): a precision (reliability) metric of the system’s output. It measures the variability of multiple likelihood ratio values obtained when a speaker recording is compared with all available recordings (if any) belonging to the same speaker (which can be the same or a different speaker). This metric is calculated using the parametric procedure described in Morrison (2011) and is reported on a ± orders of magnitude scale (log10 scale).
CLLR.mean (Likelihood Ratio Cost, accuracy only): a measure of the accuracy (validity) of the system output. According to Morrison and Enzinger (2016), “this is the same as the CLLR.pooled metric, but while all test results were aggregated to calculate CLLR.pooled, CLLR.mean is calculated on averages of groups as defined in the 95% CI metric” (a group consists of multiple likelihood ratio values as described above).
CLLR.min (Discrimination Loss): a measure of the quality of the embedding extraction phase, i.e., the quality of the score values. It is a CLLR calculated after the LR values from the test results have been optimized using the non-parametric pool-adjacent-violators (PAV) procedure, which involves training and testing on the same data. Therefore, this metric is not representative of expected performance on new test data. According to Meuwly et al. (2017), discrimination power represents the ability to distinguish between forensic comparisons where different propositions are true.
CLLR.cal (Calibration Loss): equal to the difference CLLR.pooled - CLLR.min. It measures the quality of the presentation phase, i.e., the calibration of the likelihood ratio.
EER (Equal Error Rate): another widely used metric to evaluate the system’s discrimination power. Likelihood ratio test values can be combined with some prior probabilities to obtain posterior probabilities; these can then be compared to a threshold to classify a test comparison as same speaker (prosecution hypothesis) or different speakers (defense hypothesis). In this way, false identification and false rejection error rates can be calculated as the proportion of misclassifications. The EER is obtained by adjusting prior probabilities and the threshold so that the two error rates are equal, and the resulting error rate is called the EER.